Introduction
The goal of this article is to explore the latency of different OpenAI models. When using AI models in production, latency is an important factor to consider.
Comparing Model Architectures
First, I test the latency for different OpenAI models.
I test the following models: gpt-4, gpt-4-0613, gpt-3.5-turbo, gpt-3.5-turbo-0613, gpt-3.5-turbo-16k, gpt-3.5-turbo-16k-0613, text-davinci-003, text-davinci-002, text-davinci-001, text-curie-001, text-babbage-001, text-ada-001, davinci-002, babbage-002, davinci, curie, babbage, and ada.
These are all the OpenAI models that are available for inference through the chat and completions endpoints.
The models can be divided into chat models, instruct models, and base models.
Chat models are gpt-4 and gpt-3.5 and are LLMs that are optimized for chat.
Instruct models are models that are trained with reinforcement learning through human feedback to follow instructions [1].
The most powerful OpenAI models are the gpt-4 models. The “0613” part of the model means that it is a checkpoint from 6/13/23. The gpt-3.5-turbo models are the newest and most powerful GPT-3 models. GPT-3 and GPT-4 are two different LLM model architectures. text-davinci-003 and text-davinci-002 are also GPT-3 models. text-davinci-001, text-curie-001, text-babbage-001, and text-ada-001 are GPT-3 models fine-tuned on instruction-following tasks (similar to InstructGPT), while davinci-002, babbage-002, davinci, curie, babbage, and ada are GPT-3 models that are not fine-tuned. Usuaully, the not fine-tuned models would be fine-tuned in order to make them useful for various tasks.
For the input prompt, I use “Once upon a time, in a land far, far away…”. I use this prompt to make sure that the model will not stop its output early. I also set the max tokens for the output to be 100. The input prompt is 13 tokens for a total of 113 tokens in the input + output. The temperature is set to the default value of 1. Lastly, I test the response of each models 100 times. Here is a plot of the response times for the different OpenAI models. I also include error bars which show the standard deviation of response times for each model.
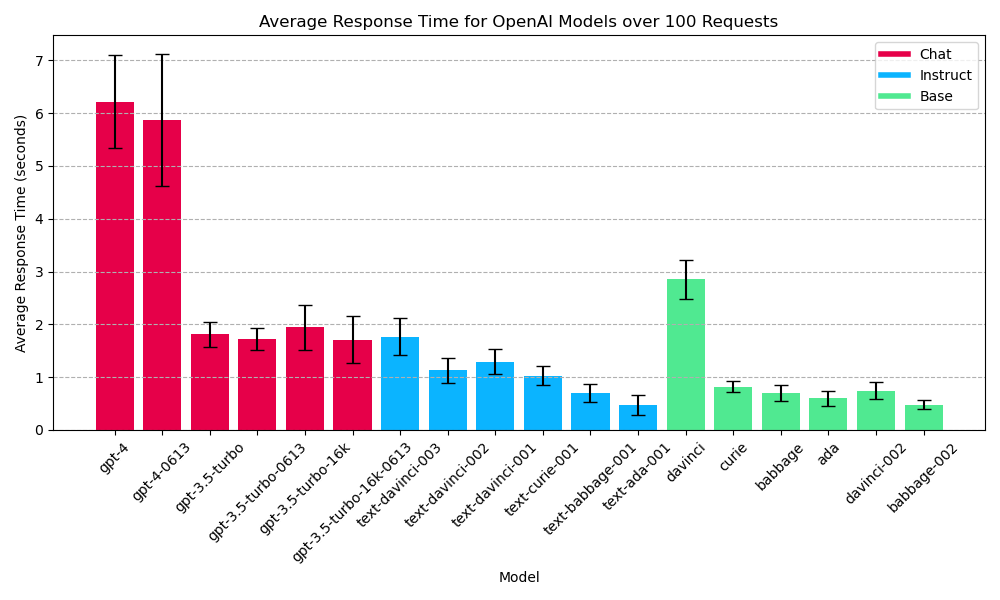 Average response time for OpenAI models
Average response time for OpenAI models
We can see that the slowest models from the group are gpt-4 and gpt-4-0613. Both of these models take about 6 seconds per request, which is two times slower than the next slowest model. The next slowest model is davinci by almost a second. Comparing text-davinci-001, text-curie-001, text-babbage-001, and text-ada-001 to davinci, curie, babbage, and ada, we see that the text models in general have faster response times. We can also see that davinci-002 and babbage-002 have faster response times than the analogous davinci and babbage.
Here is a graph of the number of parameters compared to the average response time. These are the numbers of parameters for different models [2]:
- 1.7 trillion (estimated [3]): gpt-4 and gpt-4-0613
- 175 billion: gpt-3.5-turbo, gpt-3.5-turbo-0613, gpt-3.5-turbo-16k, gpt-3.5-turbo-16k-0613, text-davinci-003, text-davinci-002, text-davinci-001, and davinci
- 13 billion: text-curie-001 and curie
- 3 billion: text-babbage-001 and babbage
- 350 million: text-ada-001 and ada
Note that the x axis is on a log scale.
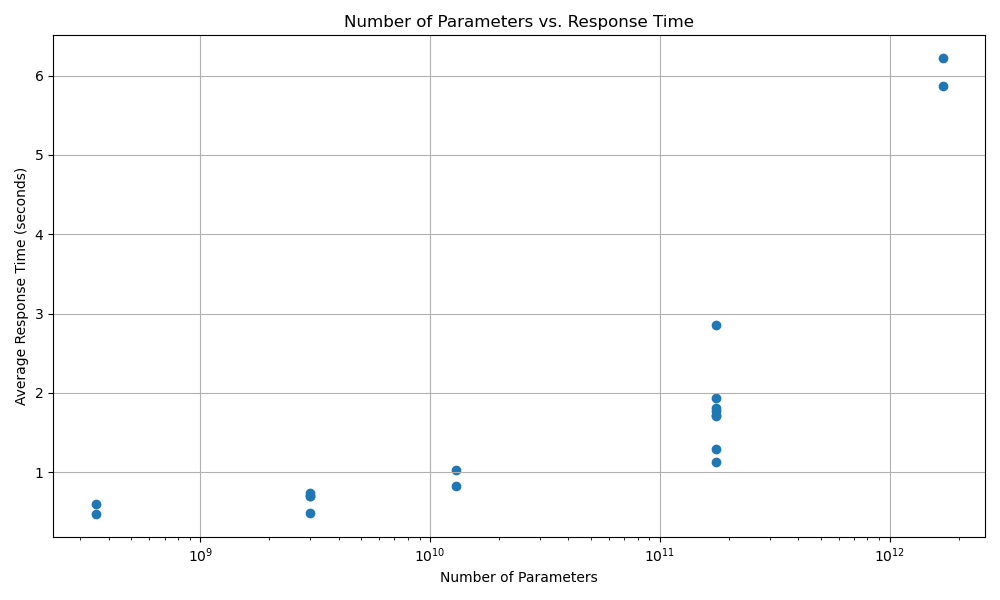 Number of parameters vs. average response time
Number of parameters vs. average response time
We see that as the number of parameters increases, the average response time increases.
Comparing Fine-Tuned vs. Base Models
OpenAI allows users to fine-tune their models through their API. There are three models available for fine-tuning: gpt-turbo-3.5, davinci-002, and babbage-002 [4]. I wanted to test how the latency of fine-tuned OpenAI models compared to the latency of base models.
I fine-tuned a model for each architecture on a Spanish to English translation dataset. Then, similarly to above, we send 100 requests to each model and measure the mean and standard deviation of the response times. The input prompt is a Spanish poem by Gustavo Adolfo Bécquer. The max tokens is set to 100 and temperature is set to the default value of 1. Here is the plot of the response times for fine-tuned vs. base models:
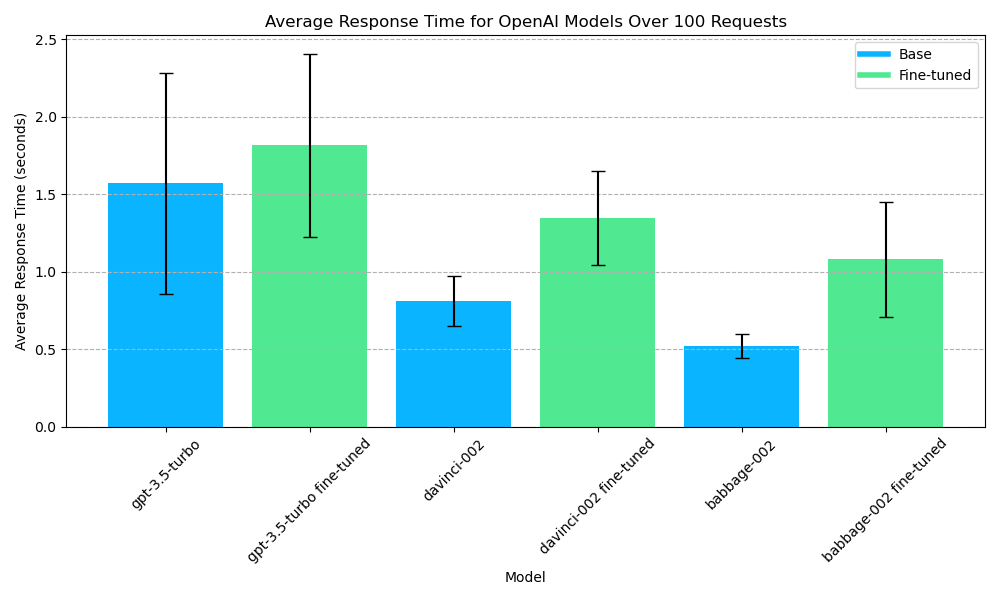 Average response time for fine-tuned vs. base OpenAI models
Average response time for fine-tuned vs. base OpenAI models
We can see that for all the model architectures, the average response time is slower for the fine-tuned model. However, for gpt-turbo-3.5, the error bars overlap.
Latency at Different Times of Day
I also tested the latency of OpenAI models at different times of day. I tested gpt-4 and gpt-3.5-turbo. For each model, I sent 5 requests every 15 minutes for 24 hours on a Wednesday and plotted the mean response time. I used the same settings as the first section: the “Once upon a time” prompt, 100 max tokens, and temperature of 1.
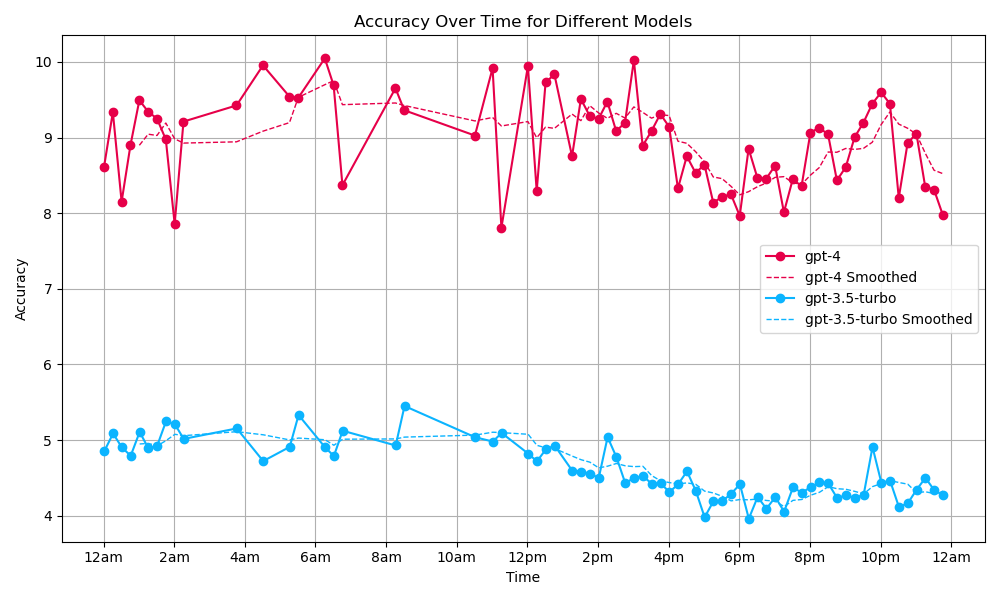 OpenAI model latency over time
OpenAI model latency over time
The entire graph is in central time. We can see that the two models follow a similar trend: the average response time is higher before 2pm or so then is lower until 10pm. We can also see that in the hours of 2am to 10am, there are a lot of dropped responses (indicated by the lack of a dot). However, more requests would be necessary to smooth this graph out. Furthermore, using the median response time may be better than using the mean.
Citations
All the code used to generate the plots can be found here.